
それでもまだ餌(feed)を食いにくるクローラーのブロックに成功しました。どうも「$(ドル)」がよくなかったようです。
以前、WordPressを利用したブログでコメント欄を解放していると、Googleサーチコンソールのカバレッジに、「feed」というページが大量に発生してしまう(登録されてしまう)問題があると知ったことから、これへの対策を打った話をしました。
ところが、しばらくしてもクローラーはふつうに巡回してきている、つまり問題はまだ解決していなかったことが判明。
ふたたび原因の究明に乗りだしたところ、クローラーの動きを制御する「robots.txt」というファイルの記述(「Disallow」部分)が、うまくできていなかったことがわかりました。
そこで、これを修正してあげると、こんどこそクローラーのブロックと「feed」の除外に成功したように思われたので、今回は、以前の話を補足するかたちで、おこなった作業の内容をお話しします。
「feed」問題の基本的な解決方法はこちら
→【除外】Search Consoleのインデックス未登録「feed」問題を解決する方法
カバレッジの「feed」へのクローラー巡回を除外する方法
Googleサーチコンソールのカバレッジから「除外 → クロール済み-インデックス未登録」へと進んでいくと、「feed」というページが大量に表示されてしまい、それによって、ほんとうに問題のあるページが埋もれてしまうことから、これへの対策をとった話を以前しました。
対策方法は、レンタルサーバーの「FTP」を利用して、「robots.txt」という、クローラー(巡回ロボット)の動きを制御するファイルを作成し、そこに、「feed」のページはクロールを「Disallow(認めない)」と書き込むというもの。
これによって、この「feed」問題は解決したかに思われたのですが、それからも定期的にクローラーはやってきていて、なんと2か月が経過しても、「feed」のページにはクローラーが巡回しにきていることが判明したのです!
ブロックしても餌(feed)を食べにくる、巡回ロボットのクローラー……。
さすがにこれはおかしいと原因を再調査してみると、サーチコンソールにはクローラーを正常にブロックできているか確認できる「テスト機能」があることがわかり、それを使用することで、「robots.txt」内の、「Disallow」のあとにつづく記述がうまくできていなかったことが発覚。
これを正確な記述に書き換えてあげたことで、テストでもブロックできていることが確認できたので、ここからは、「robots.txt」でクローラーのブロックをテストした方法と、クローラーの巡回を除外できるように変更した、「Disallow」の記述についてお話ししていきます。
「robots.txt」のブロックのテストで「Disallow」を確認
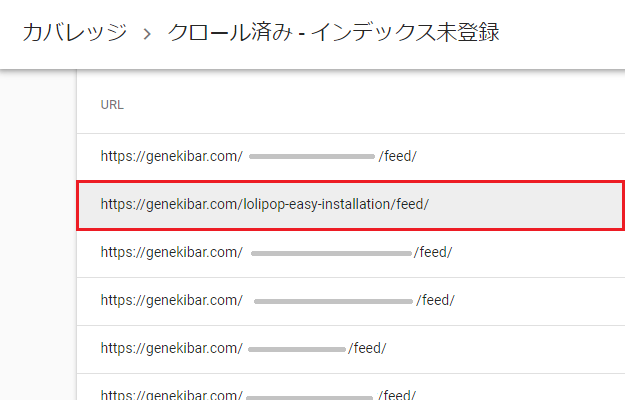
サーチコンソールのカバレッジから「クロール済み-インデックス未登録」と進んでいくと、このように、該当するページのURLが一覧で表示されますが、ここに表示されているURLは、じつはクリックできるようになっています。
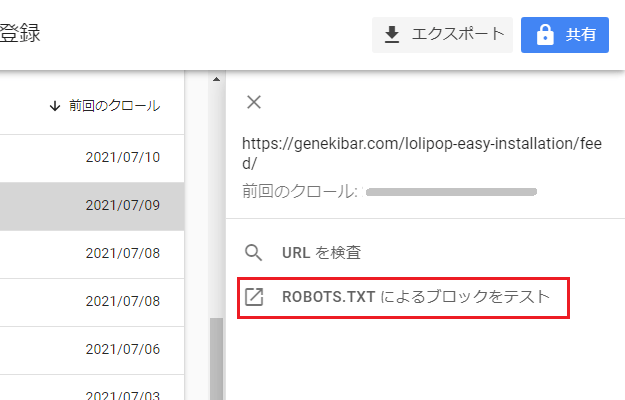
URLをクリックすると、右側から「ROBOTS.TXT によるブロックをテスト」という項目が出てくるので、こちらをクリック。
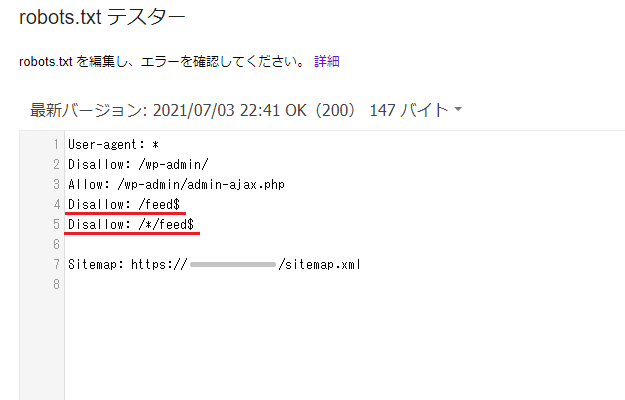
すると、「robots.txt テスター」というページがひらかれ(テスターはこちらからでもアクセス可能)、ここに「robots.txt」のファイルに書いた内容が表示されるのですが、私が以前の作業で書いた「Disallow」部分は、以下のとおりとなっていました。
Disallow: /feed$
Disallow: /*/feed$ところが、テスターの画面をよく確認してみると、
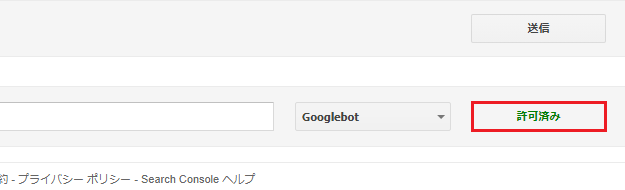
画面の下のほうに表示されていたのは「許可済み」という表記。
ようするに、これは「Disallow」部分の記述に問題があり、「feed」のページは、まだクロールが「許可」されている状態だったというわけです。
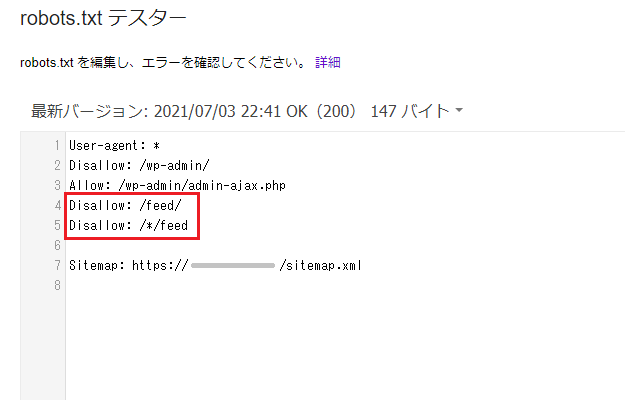
そこで、画像のとおり、ここの記述を以下のように変更(テスターは記述を直接いじれるようになっています)。
Disallow: /feed/
Disallow: /*/feed末尾(~でおわる)を意味する「$(ドルマーク)」を消して、上のほうには「/(スラッシュ)」を足してあげました(下はアスタリスク前のスラッシュはなくてもいいかもしれません)。
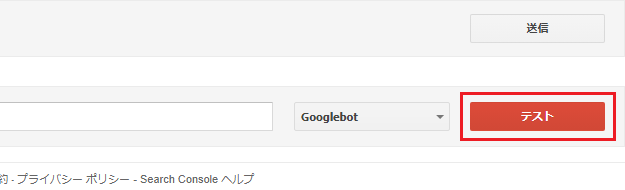
そうすると、さきほどは「許可済み」となっていたところが「テスト」に変わったので、こちらをクリックすると、
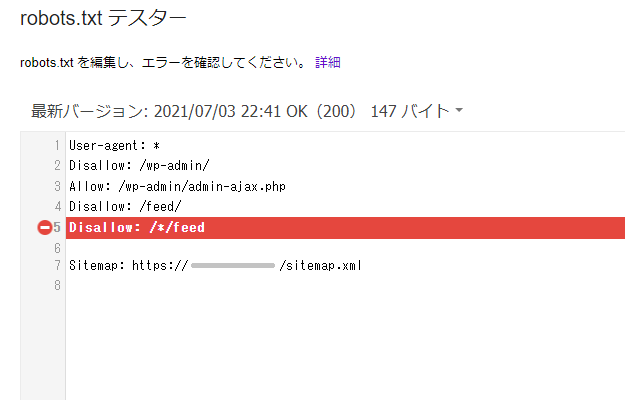
5行目の「Disallow: /*/feed」に「禁止マーク」のようなものが付き、
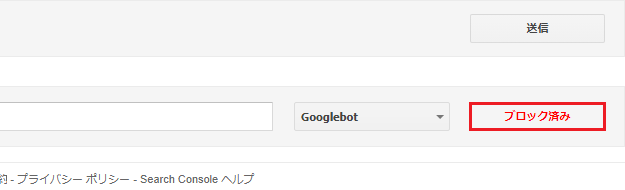
さきほどの「テスト」は、みごと「ブロック済み」に変わりました。
これで、「feed」のページを巡回しに来るクローラーを、除外することに成功したというわけです!
「robots.txt」のファイルを変更してクローラーをブロック
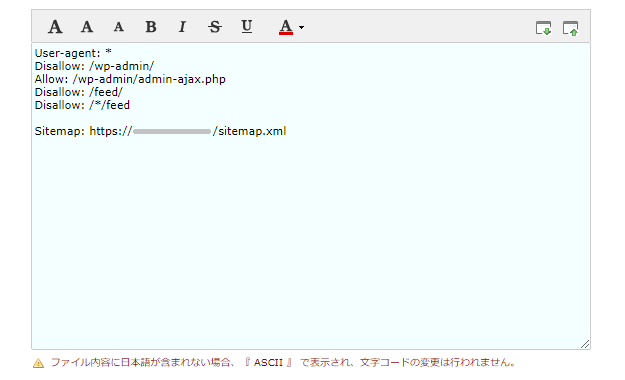
さきほどのテストで、クローラーが「feed」のページに来るのをブロックできることが確認できたので、最後に、「FTP」から「robots.txt」のファイルの内容を変更してあげました。
最終的な記述は、以下のとおりです。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /feed/
Disallow: /*/feed
Sitemap: https://〇〇〇〇.com/sitemap.xml
ちなみに、Google検索セントラル(ヘルプページのようなもの)によると、
自動クロールの過程で、Google のクローラは robots.txt ファイルに加えられた変更を検知し、キャッシュに保存されたバージョンを 24 時間おきに更新します。robots.txt ファイルを更新する
とのことで、より早く更新を反映させるには、さきほどのテスターのページにある「送信」という機能を使えばできるとのことでしたが、私の場合は、1時間もしないうちに変更が反映されていたので、これは、そのまま待っていればだいじょうぶだと思います。
サーチコンソールのカバレッジから「feed」のページを除外する方法の解決版は、以上となります。さすがに、これでできていることでしょう!
今回のまとめ
・「Disallow」以降のドルマークが原因だったもよう
・さすがにこれでできているものと思われます
以前おこなった作業で「feed」ページへのクローラーが除外できていなかったのは、「Disallow」以降の「$(ドルマーク)」が原因だったと考えられます。
テストでもブロックできていることが確認できたので、この「feed」問題は、さすがにこれでだいじょうぶでしょう。
「robots.txt」のページのつくり方に関しては、冒頭の関連記事に書いてありますので、そのへんがわからない方は、そちらをごらんいただければと思います。
経過観察中にまた問題が起きる(まだクロールされている)ようなことがあれば、また追って報告したいと思います。
また問題が起きたので対策しました
→ サーチコンソールの「feed」を完全に除外する方法は「noindex」の方だった

コメント(確認後に反映/少々お時間をいただきます)