
巡回ロボットに食わせる餌はない! カバレッジの「feed」問題を解決するため、クローラーをブロックすることにしました。
ときどき記事のコンテンツには問題はないのに、Googleの「Search Console」でモバイルユーザビリティのエラーが出ることがありますが(これは記事を更新して検証を開始すると直ることも多い)、ちょうどその流れで「カバレッジ」をながめていたとき、私はあることに気がつきました。
サーチコンソールの「除外」から確認できる「クロール済み-インデックス未登録」の項目に、「feed」というなぞのページが大量発生していたのです。
さきにいってしまうと、この「feed」自体はあっても問題はないらしく、正直いうと、そのまま放置してもよかったのです。
しかし、よく見てみると、それによってべつの深刻な問題が発生してしまう危険性があるようにも思われたので、今回はこの「feed大量発生」問題の解決策を探ることにしました。
「feed」の正体はコメントページらしい
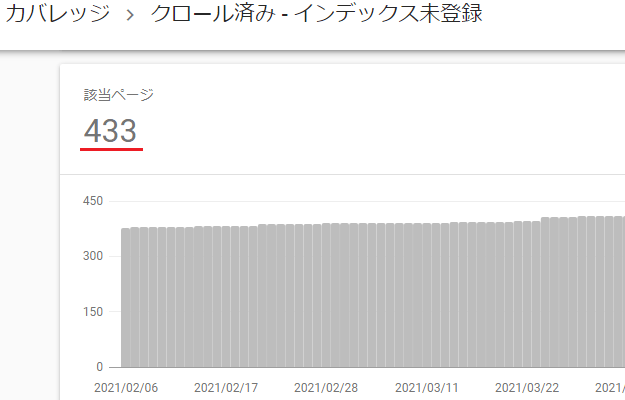
Google Search Consoleは、記事の検索パフォーマンスなどのデータ以外にも、各種エラーなども確認することができるツールですが、「カバレッジ → 除外」と進んでいくと、「クロール済み-インデックス未登録」という項目に、433件もの該当ページがあることが発覚。
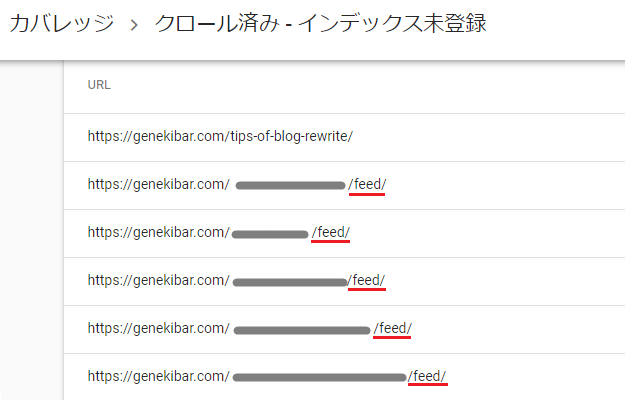
なかを確認してみると、URL末尾に「feed」というものがついたページが、ずらずらとならんでいることがわかりました。
ちなみに、この「feed」というのは、どうやらブログ(WordPress)のコメント欄をオープンにしていると自動でつくものらしく、放っておいても害はないようなので、一見するとこの問題は、放置していてもいいように思われます。
ところが、数十件程度ならまだしも、この「feed」が数百件レベルになってくると、話は変わってくるのです。
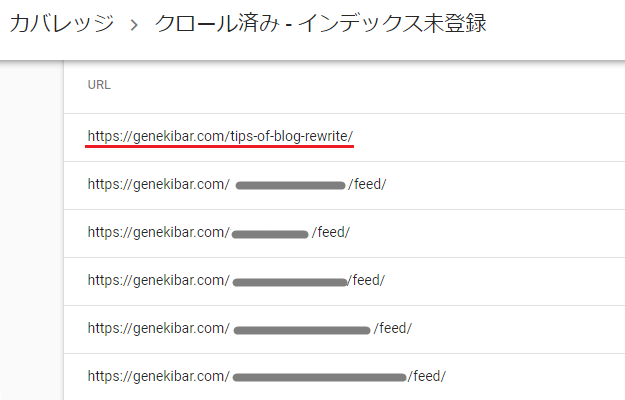
この場合、たまたまいちばん上にあったのですぐにわかりましたが、このなかには「feed」なしのページも含まれているのが大きな問題。
Googleのクローラー(巡回ロボット)によってクロール(記事がチェック)されたのに、インデックスに未登録(Web上に登録されていない)ということは、いくつかの理由があるように思われるものの、その記事が低品質とみなされてしまった可能性もあるということなのです!
いちばん上の記事は、正直いうと個人的にはかなり重要な話だったのですが、それはさておき、「feed」なしの該当ページを探していると、私はここでもある重要なことに気がついてしまいました。
「YMYL」という、お金や健康にかかわる記事がけっこうここに入っていたのです。
つまり、お金や健康ジャンルの記事が上にあがらないというのは、キーワードが引っかからないとかそういう話ではなく、その記事がGoogleによってインデックスすべきではないと判断されてしまったことで、そもそもWeb上(検索結果)に存在していないことになっていたからだったのです!
それは、いくらあがいても上がらないわけですよね。なぜなら、インデックス未登録だったのですから。
「robots.txt」でクロールを拒否(除外)する
この「feed」問題を放置しておくと、もうだめな記事はまだいいとしても、さきほどのようにまだ可能性がある記事の見直しや、本来は登録されているはずのページがこちら(ブログ)側の問題によって登録されていない、といった事態までをも見落としてしまう危険性があるように感じられました。
こういったことをすぐに把握して対処していかなければ、あとあとになって大問題に発展してしまうこともめずらしいことではないでしょう。
そこで、この問題には先手を打っておくことにしたのですが、どうやらベストな対策としては、「All In One SEO Pack」などのSEO系プラグインで除去していくのがいいとのこと。
しかし、あえてこういったものを使っていない私は、この方法をとることができませんし、ましてこのためだけに、あらたに導入する気もありませんでした。
では、どうするのか? 私は「robots.txt」というファイルに、「餌(feed)」を食いにくるクローラーを拒否する記述を追加することで、ひとまずこれ以上は増やさないという対策をとることにしたのです。
ブロックの記述でクローラーから「餌」を取り上げろ!
「robots.txt」とは、クローラー(巡回ロボット)がブログを見にくる動きに対して、認める・拒否するといった、一定の指標をしめす(動きを制御する)ことができるもので、実際にブログでこれがどのように動いているのかというのは、サーチコンソールの「robots.txt テスターで robots.txt をテストする」のページから確認することができます。
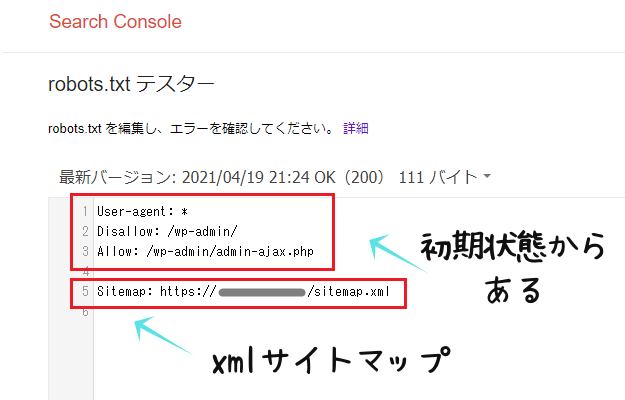
そう、じつはなにもしていなくても、WordPressの場合は最初から仮想のファイルが用意されていて、「Disallow:認めない」「Allow:認める」などと、「robots.txt」に記述されているのです。
「xmlサイトマップ」のプラグインを使用すれば、この仮想ファイルにサイトマップのURLも自動で追加されるようなので、おそらくなにもしていなければ、この状態が基本になっていることでしょう。
よって、今回の作業は、この記述に、「feed」に対するクローラーを除外する文を追加すればよく、以下の2行を加えてあげれば完了となります。
Disallow: /feed$
Disallow: /*/feed$問題は、このクローラーを制限する文をどのようにして追加するかですが、私はそれがいちばん手っ取り早いと思ったので、「robots.txt」というファイルを作成し、これをサーバーにアップロードすることにしました。
私の環境では「Disallow」以降の「feed」に「$(ドルマーク)」がついているとうまくいかないことが判明し、その後「robots.txt」では完全に除外できないことが判明。この問題は「noindex」を使用したほうがいいように思われます。くわしくはページ末尾の関連記事をごらんください。
robots.txtのファイルを作成してアップロードする
具体的な手順としては、まずは以下のファイルをメモ帳などで作成。
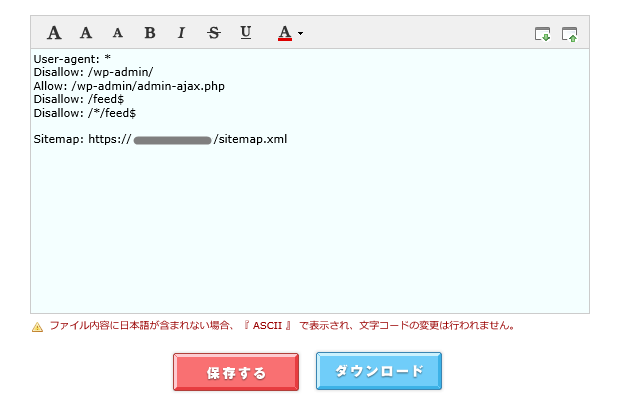
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /feed$
Disallow: /*/feed$
Sitemap: https://〇〇〇〇.com/sitemap.xmlもともとあった内容に、「feed」をブロックする2行が追加されています。
それができたら、レンタルサーバーの「FTP」をひらいて、ブログのファイルなどがたくさんならんでいるところに、「robots.txt」というファイルを作成し、そこにさきほどの内容を記述すればOK。
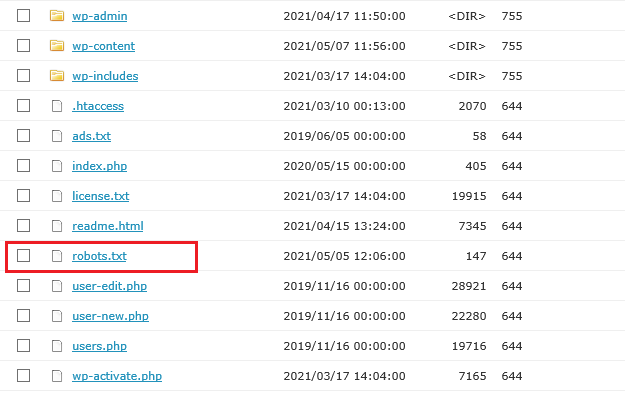
私の場合はロリポップなのでこのような感じですが、この画面で「新規ファイルを作成」を選択し(これはもうすでに作成したあとの画像です)、
ファイル名を「robots.txt」として、メモ帳などにつくっておいた内容を書き込み、あとは保存すれば完了!
ちなみに、これを作成した直後では、前述したサーチコンソールのテストツールでは確認することができないと思うのですが(まだ反映されていないため)、自身のブログのURL末尾に「/robots.txt」と入力して検索をかけることでも、「robots.txt」に書いた内容が反映されているかは確認することができます。
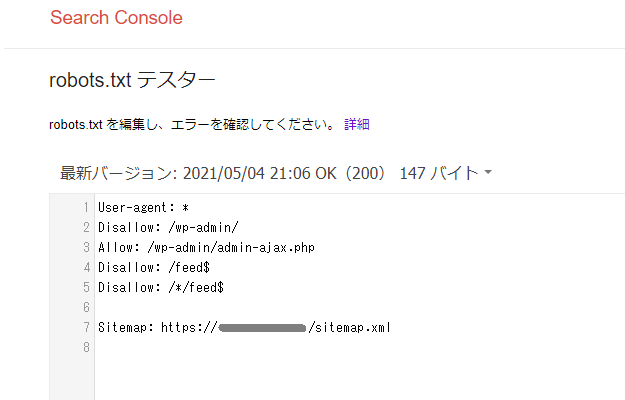
その方法でも確認することができましたし、数日後に確認してみると、こちらでもばっちり反映されていました。
サーバーに「robots.txt」を作成すると、仮想のファイルよりもこちらが優先されるとのことだったので、おそらくこれでだいじょうぶかと思います。
以上で今回の作業も終了です。
(参考:サチコのカバレッジでfeedがインデックス未登録として大量に出現/WordPress初心者に贈る!robots.txtの書き方と設定方法全手順)
今回のまとめ
・ただし、それが増えてくると、本当の問題が埋もれてしまう
・「robots.txt」のファイルを作成してブロックすればたぶんいける
この「robots.txt」でクローラーを拒否する方法は、あくまでもこれ以上増やさないことが目的で、これまでにできた「feed」を除去できるかどうかは正直いうとわからない部分もあります。
ただ、しばらく様子を見ていれば、これはわかることだと思うので、数百個の「餌」がどうなるかは、これから経過を観察したいと思います。
また、途中で、「本来は登録されているはずのページがこちら(ブログ)側の問題によって登録されていない」おそれがあると私はいいましたが、これは早くも発見してしまいました。
その問題については、また追って報告したいと思います。
新たに起きた問題はこちら
→ WordPressの年別アーカイブだけが表示されない「404」謎現象の解決方法
「feed」問題の解決版(と思った)はこちら
→【解決版】サーチコンソールの「feed」を除外する「robots.txt」の書き方
「noindex」を使用した完全解決版はこちら
→ サーチコンソールの「feed」を完全に除外する方法は「noindex」の方だった

コメント(確認後に反映/少々お時間をいただきます)
コメント一覧 (2件)
/feed$ですが、/feed/も含まれるのですか?
ドルマークは正規表現といって「文末」を意味するものです。
つまり「feedでおわる文字列」といった意味になるので「/feed/」は含まれます。
(※詳しいことはググればわかると思うので調べてみてください)
ただ関連記事にも書いてあるのですが、現在はこの「feed」は放置でもいいのではという気がしています。
記事を更新できる機会があれば、放置でいいのでは? と考えるようになった理由もお話ししたいと思います。